
Focal point - (Physical Science) - Vocab, Definition ... - focal point optics
Let i and o be the column vectors that include the samples of the 2D complex-valued input and output FOVs, respectively, as shown in Fig. 1a. Here we assume that the optical wave field can be represented using the scalar field formulation38,39,40. i and o are generated by, first, sampling the 2D input and output FOVs, and then vectorizing the resulting 2D matrices in a column-major order. Following our earlier notation, Ni and No represent the number of diffraction-limited spots/pixels on the input and output FOVs, respectively, which also define the lengths of the vectors i and o. In our simulations, we assume that the sampling period along both the horizontal and vertical directions is λ/2, where λ is the wavelength of the monochromatic scalar optical field. With this selection in our model, we include all the propagating modes that are transmitted through the diffractive layer(s).
NEEWER offers a variety of ring lights, including LED, RGB, and makeup ring lights. These professional ring lights are lightweight, portable, and ideal for ...
Focal length determines the angle of view, magnification, perspective, and depth of field of the image. Understanding focal length is essential in choosing the right lens for your photography needs. Whether you're shooting landscapes, portraits, or wildlife, selecting the right focal length will help you capture the perfect shot. To learn more about focal length, download our free 90-page eBook, An Introduction to Photography.
We use the notation \(U\left( {{{{\boldsymbol{A}}}},{{{\hat{\boldsymbol A}}}}}^{\prime } \right)\) interchangeably with \(U\left( {{{{\boldsymbol{a}}}},{{{\hat{\boldsymbol a}}}}}^{\prime } \right)\), both referring to Eq. 16. Note that, even though the transformation error and cosine similarity metrics that are given by Eqs. 5 and 16, respectively, are related to each other, they end up with different quantities. The relationship between these two metrics can be revealed by rewriting Eq. 5 as
where S refers to the number of images for each sub-category of the training image set defined by kP for k ∈ {4, 8, 16, 32, 48, 64}, which indicates a training image where k pixels out of Ni pixels are chosen to be nonzero (with all the rest of the pixels being zero). Hence, k indicates the fill factor for a given image, as shown in Supplementary Fig. S17. We choose S = 15,000 for the training and S = 7500 for the test image sets. Also, 4R in Eq. 15 indicates the four different image rotations of a given training image, where the rotation angles are determined as 0°, 90°, 180°, and 270°. For example, 16P in Eq. 15 indicates that randomly chosen 16 pixels out of 64 pixels of an image are nonzero and the remaining 48 pixels are zero. Following this formalism, we generated a total of 360K images for the training dataset and 180K for the test image dataset. Moreover, if a pixel in an image was chosen as nonzero, it took an independent random value from the set \(\left\{ {\frac{{32}}{{255}},\,\frac{{33}}{{255}},\, \cdots ,\,\frac{{254}}{{255}},\,\frac{{255}}{{255}}} \right\}\). Here the lower bound was chosen so that the “on” pixels can be well-separated from the zero-valued “off” pixels.
When light is incident on an interface between two different media with different indexes of refraction, some of the light is reflected and some is transmitted.
To further shed light on the performance of these different diffractive designs, the estimated transformations and their differences (in phase and amplitude) from the target matrices (A) are shown in Figs. 2, 5, and Supplementary Figs. S2 and S5 for different diffractive parameters. Similarly, examples of complex-valued input-output fields for different diffractive designs are compared in Figs. 3, 6 and Supplementary Figs. S3, S6 against the ground truth output fields (calculated using the target transformations), along with the resulting phase and amplitude errors at the output FOV. From these figures, it can be seen that both data-free (K = 1) and deep learning-based (K = 4) diffractive designs with the same total number of neurons can all-optically generate the desired transformation and output field patterns with negligible error when N ≥ 642 = NiNo. For N < NiNo, on the other hand, the output field amplitude and phase profiles using deep learning-based diffractive designs show much better match to the ground truth output field profiles when compared to data-free, matrix pseudoinverse-based diffractive designs (see e.g., Figs. 3, 6).
We also compared our results to a data-based iterative projection method, which can be considered as an extension of the Gerchberg-Saxton algorithm for multi-layer settings44. Using this iterative projection method44, we trained phase-only transmittance values of the diffractive layers in order to approximate the first unitary transform presented in Fig. 1 by feeding them with the corresponding ground truth input/output fields. Then, we computed the associated transformation error and the other performance metrics through the projection-based optimized neuron values. We report the results of this comparison in Supplementary Fig. S15. The transformation error, cosine similarity measure, and MSE results indicate that as the number of diffractive layers increases, the deep learning-based all-optical solutions become much more accurate in their approximation compared to the performance of iterative projection-based diffractive designs.
Focal length is determined in part by the size of the camera's sensor. For instance, because a full-frame camera has a larger sensor than a crop-sensor camera, a 50mm lens on a full-frame camera will have a wider field of view than the same lens on the crop-sensor camera.
Since scalar optical wave propagation in free space and light transmission through diffractive surfaces constitute linear phenomena, the light transmission from an input field-of-view (FOV) to an output FOV that is engineered through diffractive surfaces can be formulated using linear algebra35. As a result, together with the free space diffraction, the light transmittance patterns of diffractive surfaces (forming an optical network) collectively define a certain complex-valued all-optical linear transformation between the input and output FOVs. In this paper, we focus on designing these spatial patterns and diffractive surfaces that can all-optically compute a desired, target transformation. We demonstrate that an arbitrary complex-valued linear transformation between an input and output FOV can be realized using spatially-engineered diffractive surfaces, where each feature (neuron) of a diffractive layer modulates the amplitude and/or phase of the optical wave field. In generating the needed diffractive surfaces to all-optically achieve a given target transformation, we use both a matrix pseudoinverse-based design that is data-free as well as a data-driven, deep learning-based design method. In our analysis, we compared the approximation capabilities of diffractive surfaces for performing various all-optical linear transformations as a function of the total number of diffractive neurons, number of diffractive layers, and the area of the input/output FOVs. For these comparisons, we used as our target transformations arbitrarily generated complex-valued unitary, nonunitary and noninvertible transforms, 2D Fourier transform, 2D random permutation operation as well as high-pass filtered coherent imaging operations.
Lenscalculator
We also report the convergence analysis of our deep learning-based designs in Supplementary Fig. S16. The simulations for this convergence analysis were carried out for K = 4 using both the complex-valued and phase-only modulation layers when N = 482, 642, or 802. The MSE curves in Supplementary Fig. S16 show a monotonic decrease as the number of epochs increases during the training. On the other hand, although the general trends of the transformation error and the cosine similarity metrics are almost monotonic, they show some local variations between consecutive training epochs, as shown in Supplementary Figs. S16a, b. This behavior is expected since the diffractive network does not directly minimize the transformation error during its training; in fact, it minimizes the output MSE as given by Eq. 10. In addition to these, we observe that the diffractive network design converges after a few epochs, where the training in the subsequent epochs serves for the purpose of fine tuning of the network’s approximation performance.
\(\left| {\angle {{{\boldsymbol{A}}}} - \angle \widehat {{{\boldsymbol{A}}}}^\prime } \right|_\pi\) indicates the wrapped phase difference between the ground truth and the normalized all-optical transformation
where a is the vectorized form of the target transformation matrix A, i.e., vec(A) = a. We included a scalar, normalization coefficient (m) in Eq. 5 so that the resulting difference term does not get affected by a diffraction-efficiency related scaling mismatch between A and A′; also note that we assume a passive diffractive layer without any optical gain, i.e., |t1[l]| ≤ 1 for all \(l \in \left\{ {1,2, \cdots ,\,N_{L_1}} \right\}\). As a result of this, we also introduced in Eq. 5, \(m{{{\boldsymbol{t}}}}_1 = {{{\hat{\boldsymbol t}}}}_1\).
Li, J. X. et al. Spectrally encoded single-pixel machine vision using diffractive networks. Sci. Adv. 7, eabd7690 (2021).
In summary, the vector t1 that includes the transmittance values of the diffractive layer is computed from a given, target transformation vector, a, using Eqs. 6 and 9, and then the resulting estimate transformation vector, a′, is computed using Eq. 4. Finally, A′, is obtained from a′ by reversing the vectorization operation.
After generating the 2D matrix by applying the appropriate vectorization operation, we also normalize the resulting matrix with its largest singular value, to prevent the amplification of the orthonormal components.
As our all-optical transformation performance metrics, we used (i) the transformation error, (ii) the cosine similarity between the ground truth and the estimate transformation matrices, (iii) normalized output MSE and (iv) the mean output diffraction efficiency.
2 Followers, 0 Following, 3 Posts - Point of View Optical Syracuse (@point_of_view_optical_syracuse) on Instagram: "Eye Exams, Glasses and Contacts!"
Mm to inches conversion chart near 30.9 mm ; 26.9 mm, = 1.06 inch ; 27.9 mm, = 1.1 inch ; 28.9 mm, = 1.14 inch ; 29.9 mm, = 1.18 inch.
a Schematic of a K-layer diffractive network, that all-optically performs a linear transformation between the input and output fields-of-views that have Ni and No pixels, respectively. The all-optical transformation matrix due to the diffractive layer(s) is given by A′. b. The magnitude and phase of the ground truth (target) input-output transformation matrix, which is the 2D Fourier transform matrix. c All-optical transformation errors (see Eq. 5). The x-axis of the figure shows the total number of neurons (N) in a K-layered diffractive network, where each diffractive layer includes N/K neurons. Therefore, for each point on the x-axis, the comparison among different diffractive designs (colored curves) is fair as each diffractive design has the same total number of neurons available. The simulation data points are shown with dots and the space between the dots are linearly interpolated. d Cosine similarity between the vectorized form of the target transformation matrix in (b) and the resulting all-optical transforms (see Eq. 16). e Output MSE between the ground-truth output fields and the estimated output fields by the diffractive network (see Eq. 18). f The diffraction efficiency of the designed diffractive networks (see Eq. 19)
where X is the diffraction efficiency term which is given by Eq. 19. In Eqs. 24 and 25, cM, cD and α are the user-defined weights. In earlier designs where the diffraction efficiency has not been penalized or taken into account during the training phase, cM and cD were taken as 1 and 0, respectively.
The permutation (P) operation performs a one-to-one mapping of the complex-value of each pixel on the input FOV onto a different location on the output FOV. Hence the randomly selected transformation matrix (A = P) associated with the permutation operation has only one nonzero element along each row, whose value equals to 1, as shown in Fig. 10b.
refer to the ground truth and the estimated output field by the diffractive network, respectively, for the sth input field in the training dataset, is. The subscript c indicates the current state of the all-optical transformation at a given iteration of the training that is determined by the current transmittance values of the diffractive layers. The constant σs normalizes the energy of the ground truth field at the output FOV and can be written as
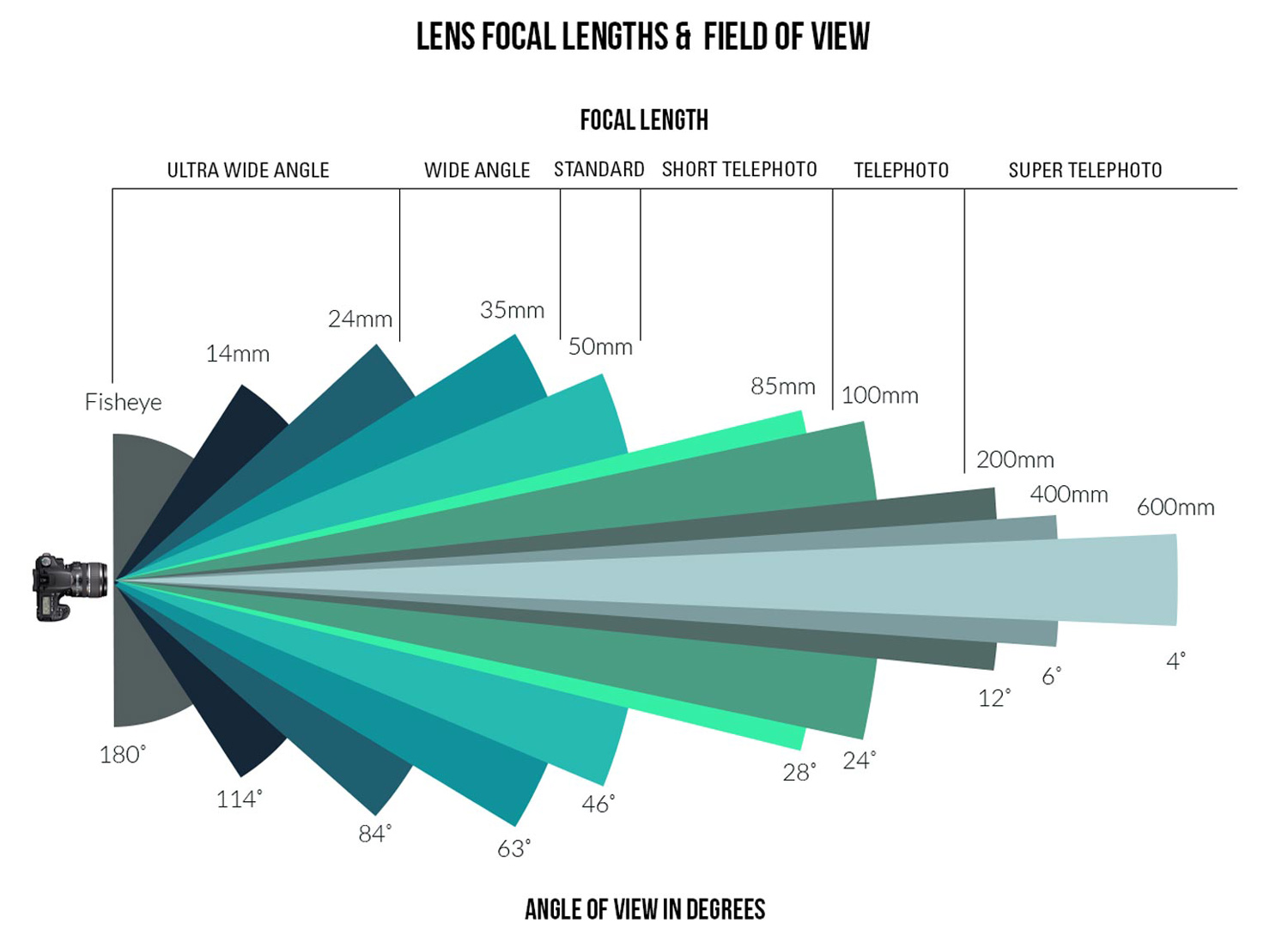
Focal lengths range from 8mm to 2000mm. When it comes to focal length, there are three main type of lens: wide-angle, normal, and telephoto. Wide-angle lenses have a focal length of less than 35mm. They are great for capturing landscapes, architecture, and interiors because they provide a wider field of view, meaning they can capture more in the frame. Normal lenses have a focal length of between 35mm to 70mm. They are also known as standard lenses. Normal lenses capture the subject without distorting it, which makes them perfect for everyday photography, portraits, and street photography. Telephoto lenses, which have a focal length greater than 70mm, are ideal for capturing distant subjects, such as wildlife, sports, and events. They magnify the subject and compress the background. Macro lenses, which offer significant magnification (1:1, for instance), come in a variety of focal lengths. With these lenses, focal length determines how close you need to be to your subject to capture a sharp magnified image. The longer the focal length, the further away your camera can be from your subject without losing focus.
The magnitude and phase of the normalized output fields and the differences of these quantities with respect to the ground truth are shown
Diffractive all-optical transformations and their differences from the ground truth, target transformation (A) presented in Fig. 10b
Kulce, O., Onural, L. & Ozaktas, H. M. Evaluation of the validity of the scalar approximation in optical wave propagation using a systems approach and an accurate digital electromagnetic model. J. Mod. Opt. 63, 2382–2391 (2016).
Finally, we should emphasize that for diffractive networks that have more than one layer, the transmittance values of the neurons of different layers appear in a coupled, multiplicative nature within the corresponding matrix-vector formulation of the all-optical transformation between the input and output FOVs35. Hence, a one-step, matrix pseudoinverse-based design strategy cannot be applied for multi-layered diffractive networks in finding all the neuron transmittance values. Moreover, for diffractive designs with a large N, the sizes of the matrices that need to undergo the pseudoinverse operation grow exponentially, which drastically increases the computational load and may prevent performing matrix pseudoinverse computations due to limited computer memory and computation time. This also emphasizes another important advantage of the deep learning-based design methods which can handle much larger number of diffractive neurons to be optimized for a given target transformation, thanks to the efficient error back-propagation algorithms and computational tools that are available. Similarly, if Ni and No are increased as the sizes of the input and output FOVs are enlarged, the total number of diffractive neurons needed to successfully approximate a given complex-valued linear transformation will accordingly increase to D = NiNo, which indicates the critical number of total diffractive features (marked with the vertical dashed lines in our performance metrics related figures).
where (it, jt) pair is randomly chosen for each t. We used T = 105 in our simulations. As a result, for each t in Eq. 21, (it, jt) and (θ1, θ2, θ3) were chosen randomly. It is straightforward to show that the resulting R matrix in Eq. 21 is a unitary matrix.
Throughout the paper, we use \(\| {{{{\boldsymbol{A}}}} - {{{\hat{\boldsymbol {A}}}}}^\prime } \|^2\)and \(\| {{{{\boldsymbol{a}}}} - {{{\hat{\boldsymbol {a}}}}}^\prime } \|^2\) interchangeably both referring to Eq. 5 and define them as the all-optical transformation error. We also refer to a, a′ and \({{{\hat{\boldsymbol a}}}}^\prime\) as the target transformation (ground truth), estimate transformation and normalized estimate transformation vectors, respectively.

Through our results and analysis, we showed that it is possible to synthesize an arbitrary complex-valued linear transformation all-optically using diffractive surfaces. We covered a wide range of target transformations, starting from rather general cases, e.g. arbitrarily generated unitary, nonunitary (invertible) and noninvertible transforms, also extending to more specific transformations such as the 2D Fourier transform, 2D permutation operation as well as high-pass filtered coherent imaging operation. In all the linear transformations that we presented in this paper, the diffractive networks realized the desired transforms with negligible error when the total number of neurons reached N ≥ NiNo. It is also important to note that the all-optical transformation accuracy of the deep learning-based diffractive designs improves as the number of diffractive layers is increased, e.g., from K = 1, 2 to K = 4. Despite sharing the same number of total neurons in each case (i.e., \(N = \mathop {\sum}\nolimits_{k = 1}^K {N_{L_k}}\)), deep learning-based diffractive designs prefer to distribute these N trainable diffractive features/neurons into multiple layers, favoring deeper diffractive designs overall.
In this sub-section, we present diffractive designs that perform high-pass filtered coherent imaging, as shown in Supplementary Fig. S7. This high-pass filtering transformation is based on the Laplacian operator described in Section 4.4. Similar to the 2D discrete Fourier transform operation demonstrated earlier, diffractive surface-based solutions to high-pass filtered coherent imaging are not based on a low numerical aperture assumption or the paraxial approximation, and provide an axially compact implementation with a significantly smaller distance between the input-output planes (e.g., <50λ); furthermore, these diffractive designs can handle large input/output FOVs without suffering from aberrations.
To compute the nonunitary but invertible matrices, we first generated two unitary matrices RU and RV, as described by Eqs. 20 and 21, and then a diagonal matrix X. The diagonal elements of X takes uniformly, independently and identically generated random real values in the range [0.3, 1], where the lower limit is determined to be large enough to prevent numerical instabilities and the upper limit is determined to prevent amplification of the orthonormal components of RU and RV. Then, the nonunitary but invertible matrix is generated as \({{{\boldsymbol{R}}}}_U{{{\boldsymbol{XR}}}}_V^H\), which is in the form of the SVD of the resulting matrix. It is straightforward to show that the resulting matrix is invertible. However, to make sure that it is nonunitary, we numerically compute its Hermitian and its inverse separately, and confirm that they are not equal. Similarly, to compute the noninvertible transformation matrix, as shown in e.g., Supplementary Fig. S4b, we equated the randomly chosen half of the diagonal elements of X to zero and randomly chose the remaining half to be in the interval [0.3, 1]. Following this, we computed the noninvertible matrix as \({{{\boldsymbol{R}}}}_U{{{\boldsymbol{XR}}}}_V^H\), by re-computing new unitary matrices RU and RV, which end up to be completely different from the RU and RV matrices that were computed for the nonunitary and invertible transform.
In our numerical simulations, the chosen input and output FOV sizes are both 8 × 8 pixels. Hence, the target linear transforms, i.e., A matrices, have a size of No × Ni = 64 × 64. For a diffractive design that has a single diffractive surface (K = 1), the chosen axial distances are d1 = λ and d2 = 4λ. For the networks that have two diffractive surfaces (K = 2), the chosen axial distances are d1 = λ and d2 = d3 = 4λ. Finally, for the 4-layered diffractive network (K = 4), the axial distances are chosen as d1 = λ and d2 = d3 = d4 = 4λ. These axial distances can be arbitrarily changed without changing the conclusions of our analysis; they were chosen large enough to neglect the near-field interactions between successive diffractive layers, and small enough to perform optical simulations with a computationally feasible wave propagation window size. We chose our 2D wave propagation window as \(\sqrt{N_d} \times \sqrt{N_d} = 144 \times 144\), which ends up with a size of 1442 × 1442 for Hd matrices, resulting in ~430 Million entries in each Hd matrix.
On the other hand, for data-driven, deep learning-based diffractive designs, one of the key observations is that, as the number of diffractive layers (K), increases, the all-optical transformation error decreases for the same N. Stated differently, deep learning-based, data-driven diffractive designs prefer to distribute/divide the total number of neurons (N) into different, successive layers as opposed having all the N neurons at a single, large diffractive layer; the latter, deep learning-designed K = 1, exhibits much worse all-optical transformation error compared to e.g., K = 4 diffractive layers despite the fact that both of these designs have the same number of trainable neurons (N). Furthermore, as illustrated in Fig. 1, Supplementary Fig. S1, Fig. 4, and Supplementary Fig. S4, deep learning-based diffractive designs with K = 4 layers match the transformation error performance of data-free designs based on matrix pseudoinversion and also exhibit negligible transformation error for N ≥ 642 = NiNo. However, when N < 642 the deep learning-based diffractive designs with K = 4 layers achieve smaller transformation errors compared to data-free diffractive designs that have the same number of neurons. Similar conclusions can be made in Fig. 1e, Supplementary Fig. S1e, Fig. 4e, and Supplementary Fig. S4e, by comparing the mean-squared-error (MSE) values calculated at the output FOV using test images (input fields). For N ≥ 642 = NiNo the deep learning-based diffractive designs (K = 4) along with the data-free diffractive designs achieve output MSE values that approach ~0, similar to the all-optical transformation errors that approach ~0 in Fig. 1c, Supplementary Fig. S4c, Fig. 4c, and Supplementary Fig. S7c. However for designs that have smaller number of neurons, i.e., N < NiNo, the deep learning-based diffractive designs with K = 4 achieve much better MSE at the output FOV compared to data-free diffractive designs that have same number of neurons (N).
focallength中文
In summary, an optical network that includes K diffractive surfaces can be optimized using deep learning through training examples of input/output fields that correspond to a target transformation, A. Starting with the next section, we will analyze and compare the resulting all-optical transformations that can be achieved using data-driven (deep learning-based) as well as data-free designs that we introduced.
Our results reported in Supplementary Fig. S7 also exhibit a similar performance to the previously discussed all-optical transformations, indicating that the pseudoinverse-based diffractive designs and the deep learning-based designs are successful in their all-optical approximation of the target transformation, reaching a transformation error and output MSE of ~0 for N ≥ NiNo. Same as in other transformations that we explored, deep learning-based designs offer significant advantages compared to their data-free counterparts in the diffraction efficiency that is achieved at the output FOV. The estimated sample transformations and their differences from the ground truth transformation are shown in Supplementary Fig. S8. Furthermore, as can be seen from the estimated output images and their differences with respect to the corresponding ground truth images (shown in Supplementary Fig. S9), the diffractive designs can accurately perform high-pass filtered coherent imaging for N ≥ NiNo, and for N < NiNo deep learning-based diffractive designs exhibit better accuracy in approximating the target output field, which are in agreement with our former observations in earlier sections.
We also assume that the forward propagating optical fields are zero outside of the input FOV and outside of the transmissive parts of each diffractive surface, so that we solely analyze the modes that are propagating through the transmissive diffractive layers. This is not a restrictive assumption as it can be simply satisfied by introducing light blocking, opaque materials around the input FOV and the diffractive layers. Furthermore, although the wave field is not zero outside of the output FOV, we only formulate the optical wave propagation between the input and output FOVs since the complex-valued transformation (A) that we would like to approximate is defined between i and o. As a result of these, we delete the appropriate rows and columns of Hd, which are generated based on Eq. 1. We denote the resulting matrix as \({{{\boldsymbol{H}}}}_d^\prime\).
Spatially-engineered diffractive surfaces have emerged as a powerful framework to control light-matter interactions for statistical inference and the design of task-specific optical components. Here, we report the design of diffractive surfaces to all-optically perform arbitrary complex-valued linear transformations between an input (Ni) and output (No), where Ni and No represent the number of pixels at the input and output fields-of-view (FOVs), respectively. First, we consider a single diffractive surface and use a matrix pseudoinverse-based method to determine the complex-valued transmission coefficients of the diffractive features/neurons to all-optically perform a desired/target linear transformation. In addition to this data-free design approach, we also consider a deep learning-based design method to optimize the transmission coefficients of diffractive surfaces by using examples of input/output fields corresponding to the target transformation. We compared the all-optical transformation errors and diffraction efficiencies achieved using data-free designs as well as data-driven (deep learning-based) diffractive designs to all-optically perform (i) arbitrarily-chosen complex-valued transformations including unitary, nonunitary, and noninvertible transforms, (ii) 2D discrete Fourier transformation, (iii) arbitrary 2D permutation operations, and (iv) high-pass filtered coherent imaging. Our analyses reveal that if the total number (N) of spatially-engineered diffractive features/neurons is ≥Ni × No, both design methods succeed in all-optical implementation of the target transformation, achieving negligible error. However, compared to data-free designs, deep learning-based diffractive designs are found to achieve significantly larger diffraction efficiencies for a given N and their all-optical transformations are more accurate for N < Ni × No. These conclusions are generally applicable to various optical processors that employ spatially-engineered diffractive surfaces.
Focal length
Knill, E., Laflamme, R. & Milburn, G. J. A scheme for efficient quantum computation with linear optics. Nature 409, 46–52 (2001).
The deep learning models reported in this work used standard libraries and scripts that are publicly available in TensorFlow. All the data and methods needed to evaluate the conclusions of this work are presented in the main text. Additional data can be requested from the corresponding author.
as shown in Fig. 1a. Here d1 is the axial distance between the input FOV and the first diffractive layer, dK+1 is the axial distance between the Kth layer and the output FOV, and dl for l ∈ {2, 3,⋯, K} is the axial distance between the (l − 1)th and lth diffractive layers (see Fig. 1a). Also, Tl for l ∈ {1, 2, ⋯, K} is the complex-valued light transmission matrix of the lth layer. The size of \({{{\boldsymbol{H}}}}_{d_1}^\prime\) is \(N_{L_1} \times N_i\), the size of \({{{\boldsymbol{H}}}}_{d_{K + 1}}^\prime\) is \(N_o \times N_{L_K}\) and the size of \({{{\boldsymbol{H}}}}_{d_l}^\prime\) is \(N_{L_l} \times N_{L_{l - 1}}\) for l ∈ {2, 3, ⋯, K}, where \(N_{L_l}\) is the number of diffractive neurons at the lth diffractive layer. Note that, in our notation in Eq. 2, we define o′ as the calculated output by the diffractive system, whereas o refers to the ground truth/target output in response to i. The matrix A′ in Eq. 2, that is formed by successive diffractive layers/surfaces, represents the all-optical transformation performed by the diffractive network from the input FOV to the output FOV. Note that this formalism does not aim to optimize the diffractive system in order to implement only one given pair of input-output complex fields; instead it aims to all-optically approximate an arbitrary complex-valued linear transformation, A.
Different from the numerical pseudoinverse-based design method described in the previous section, which is data-free in its computational steps, deep learning-based design of diffractive layers utilize a training dataset containing examples of input/output fields corresponding to a target transformation A. In a K-layered diffractive network, our optical forward model implements Eq. 2, where the diagonal entries of each Tl matrix for l ∈ {1, 2, ⋯, K} become the arguments subject to the optimization. At each iteration of deep learning-based optimization during the error-back-propagation algorithm, the complex-valued neuron values are updated to minimize the following normalized mean-squared-error loss function:
To create the unitary transformations, as presented in Fig. 1b and Supplementary Fig. S1b, we first generated a complex-valued Givens rotation matrix, which is defined for a predetermined i,j ∈ {1, 2, ⋯, Ni} and i ≠ j pair as
For example, if you're shooting with a telephoto lens and using a wide aperture, like f/2.8, the subject will be in sharp focus while the background will be blurry. This is ideal for portraits, where you want to isolate the subject from the background.
Luo, Y. et al. Design of task-specific optical systems using broadband diffractive neural networks. Light Sci. Appl. 8, 112 (2019).
In this paper, we used the same input (i) image dataset for all the transformation matrices (A) that we utilized as our testbed. However, since the chosen linear transforms are different, the ground truth output fields are also different in each case, and were calculated based on o = Ai. Sample images from the input fields can be seen in Supplementary Fig. S17.
As discussed in the section “Deep learning-based synthesis of an arbitrary complex-valued linear transformation using diffractive surfaces (K ≥ 1)“, our forward model implements Eq. 2 and the DFT operations are performed using the fast Fourier transform algorithm42. In our deep learning models, we chose the loss function as shown in Eq. 10. All the networks were trained using Python (v3.6.5) and TensorFlow (v1.15.0, Google Inc.), where the Adam optimizer was selected during the training. The learning rate, batch size and the number of training epochs were set to be 0.01, 8 and 50, respectively.
a Schematic of a K-layer diffractive network, that all-optically performs a linear transformation between the input and output fields-of-views that have Ni and No pixels, respectively. The all-optical transformation matrix due to the diffractive layer(s) is given by A′. b. Real and binary-valued ground truth (target) input-output transformation matrix, corresponding to a permutation operation. c All-optical transformation errors (see Eq. 5). The x-axis of the figure shows the total number of neurons (N) in a K-layered diffractive network, where each diffractive layer includes N/K neurons. Therefore, for each point on the x-axis, the comparison among different diffractive designs (colored curves) is fair as each diffractive design has the same total number of neurons available. The simulation data points are shown with dots and the space between the dots are linearly interpolated. d Cosine similarity between the vectorized form of the target transformation matrix in (b) and the resulting all-optical transforms (see Eq. 16). e Output MSE between the ground-truth output fields and the estimated output fields by the diffractive network (see Eq. 18). f The diffraction efficiency of the designed diffractive networks (see Eq. 19)
CameraSize comparison withlens
where E[∙] is the expectation operator and ST is the total number of the image samples in the test dataset. The vectors os = Ais and \({{{\boldsymbol{o}}}}_s^\prime = {{{\boldsymbol{A}}}}^\prime {{{\boldsymbol{i}}}}_s\) represent the ground truth and the estimated output fields (at the output FOV), respectively, for the sth input image sample in the dataset, is. The normalization constant, σs is given by Eq. 12, and \(\sigma _s^\prime\), can be computed from Eq. 13, by replacing \(\sigma _s^\prime\) and \({{{\boldsymbol{o}}}}_s^\prime\) by \(\sigma _{s,c}^\prime\) and \({{{\boldsymbol{o}}}}_{s,c}^\prime\), respectively.
Finally, we chose the mean diffraction efficiency of the diffractive system as our last performance metric, which is computed as
2021212 — Comments Section ... look for "individually accessible" there are a number of strips that will do it. popular ones are WS2812. There are a number ...
The first metric, the transformation error, is defined in Eq. 5, which was used for both pseudoinverse-based diffractive designs and deep learning-based designs. The second chosen metric is the cosine similarity between two complex-valued matrices, which is defined as
The authors acknowledge the US Air Force Office of Scientific Research (AFOSR), Materials with Extreme Properties Program funding (FA9550-21-1-0324). O.K. acknowledges the partial support of the Fulbright Commission of Turkey.
In our analysis reported so far, there are some practical factors that are not taken into account as part of our forward optical model, which might degrade the performance of diffractive networks: (1) material absorption, (2) surface reflections, and (3) fabrication imperfections. By using materials with low loss and appropriately selected 3D fabrication methods, these effects can be made negligible compared with the optical power of the forward propagating modes within the diffractive network. Alternatively, one can also include such absorption- and reflection-related effects as well as mechanical misalignments (or fabrication imperfections) as part of the forward model of the optical system, which can be better taken into account during the deep learning-based optimization of the diffractive layers. Importantly, previous experimental studies28,29,32,34 reported on various diffractive network applications indicate that the impact of fabrication errors, reflection and absorption-based losses are indeed small and do not create a significant discrepancy between the predictions of the numerical forward models and the corresponding experimental measurements.
Depth of field
Focal length determines numerous important elements of the photographic process, including field of view, magnification, and depth of field. Understanding focal length is essential if you want to create compelling and captivating photographs. Let’s take a closer look at focal length in photography.
The magnitude and phase of the normalized output fields and the differences of these quantities with respect to the ground truth are shown. \(\left| {\angle {{{\boldsymbol{o}}}} - \angle \widehat {{{\boldsymbol{o}}}}^\prime } \right|_\pi\) indicates wrapped phase difference between the groundtruth and the normalized output field
where ⊗ and the superscript T represent the Kronecker product and the matrix transpose operator, respectively. Since the elements of vec(T1) are nonzero only for the diagonal elements of T1, Eq. 3 can be further simplified as
In this subsection, we presented diffractive designs that successfully approximated arbitrary complex-valued transformations, where the individual elements of target A matrices (shown in Fig. 1b, Supplementary Fig. S1b, Fig. 4b, and Supplementary Fig. S4b) were randomly and independently generated as described in Section 4.4. Our results confirm that, for a given total number of diffractive features/neurons (N) available, building deeper diffractive networks where these neurons are distributed across multiple, successive layers, one following the other, can significantly improve the transformation error, output field accuracy and the diffraction efficiency of the whole system to all-optically implement an arbitrary, complex-valued target transformation between an input and output FOV. Starting with the following subsection, we focus on some task-specific all-optical transformations, which are frequently used in various optics and photonics applications.
In this section, we focus on data-free design of a single diffractive layer (K = 1), in order to determine the diagonal entries of T1 such that the resulting transformation matrix, A′ which is given by Eq. 2, approximates the transformation matrix A. To accomplish this, we first vectorize A′ in a column-major order and write it as35
where U and V are orthonormal matrices and Σ is a diagonal matrix that contains the singular values of \({\boldsymbol{H}}^\prime\). U, V, and Σ form the \({{{\boldsymbol{H}}}}^\prime\) matrix as
Goodman, J. W. & Woody, L. M. Method for performing complex-valued linear operations on complex-valued data using incoherent light. Appl. Opt. 16, 2611–2612 (1977).
In fact, deep learning-based, data-driven diffractive designs can be made even more photon efficient by restricting each diffractive layer to be a phase-only element (i.e., |t| = 1 for all the neurons) during the iterative learning process of a target complex-valued transformation. To demonstrate this capability with increased diffraction efficiency, we also designed diffractive networks with phase-only layers. The all-optical transformation performance metrics of these phase-only diffractive designs are summarized in Supplementary Figs. S10–S13, corresponding to the same arbitrarily selected unitary transform (Fig. 1), nonunitary but invertible transform (Fig. 4), the 2D Fourier transform (Fig. 7) and the randomly selected permutation operation (Fig. 10), respectively. These results indicate that much better output diffraction efficiencies can be achieved using phase-only diffractive networks, with some trade-off in the all-optical transformation performance. The relative increase in the transformation errors and the output MSE values that we observed in phase-only diffractive networks is caused by the reduced degrees of freedom in the diffractive design since |t| = 1 for all the neurons. Regardless, by increasing the total number of neurons (N > NiNo), the phase-only diffractive designs approach the all-optical transformation performance of their complex-valued counterparts designed by deep learning, while also providing a much better diffraction efficiency at the output FOV (see Supplementary Figs. S10–S13). Note also that, while the phase-only diffractive layers are individually lossless, the forward propagating optical fields still experience some power loss due to the opaque regions that are assumed to surround the diffractive surfaces (which is a design constraint as detailed in the section “Formulation of all-optical transformations using diffractive surfaces”). In addition to these losses, the field energy that lies outside of the output FOV is also considered a loss from the perspective of the target transformation, which is defined between the input and output FOVs.
where i2D and o2D represent the 2D fields on the input and output FOVs, respectively, and \(n,\,m,\,p,\,q \in \left\{ { - \frac{{\sqrt {N_i} }}{2},\, - \frac{{\sqrt {N_i} }}{2} + 1, \cdots ,\,\frac{{\sqrt {N_i} }}{2} - 1} \right\}\). Here we assume that the square-shaped input and output FOVs have the same area and number of pixels, i.e., Ni = No. Moreover, since we assume that the input and output FOVs are located at the center of their associated planes, the space and frequency indices start from \(- \sqrt {N_i} /2\). Therefore, the A matrix associated with the 2D centered DFT, which is shown in Fig. 7b, performs the transform given in Eq. 22.
Kulce, O. & Onural, L. Power spectrum equalized scalar representation of wide-angle optical field propagation. J. Math. Imaging Vis. 60, 1246–1260 (2018).
To compare the performance of all-optical transformations that can be achieved by different diffractive designs, Fig. 1c, Supplementary Fig. S1c, Fig. 4c, and Supplementary Fig. S4c report the resulting transformation errors for the above-described testbeds (A matrices) as a function of N and K. It can be seen that, in all of the diffractive designs reported in these figures, there is a monotonic decrease in the transformation error as the total number of neurons in the network increases. In data-free, matrix pseudoinverse-based designs (K = 1), the transformation error curves reach a baseline, approaching ~0 starting at N = 642. This empirically-found turning point of the transformation error at N = 642 also coincides with the limit of the information processing capacity of the diffractive network dictated by Dmax = NiNo = 642 35. Beyond this point, i.e., for N > 642, the all-optical transformation errors of data-free diffractive designs remain negligible for these complex-valued unitary as well as nonunitary transformations defined in Fig. 1b, Supplementary Fig. S1b, Fig. 4b, and Supplementary Fig. S4b.

Also, the complex valued \(\sigma _{s,c}^\prime\) is calculated to minimize Eq. 10. It can be computed by taking the derivative of \(\| {{{{\tilde{\boldsymbol {o}}}}}_s - {{{\tilde{\boldsymbol {o}}}}}_{s,c}^\prime } \|^2\) with respect to \(\sigma _{s,c}^{\prime \ast }\), which is the complex conjugate of \(\sigma _{s,c}^\prime\), and then equating the resulting expression to zero43, which yields:
Mengu, D., Rivenson, Y. & Ozcan, A. Scale-, shift-, and rotation-invariant diffractive optical networks. ACS Photonics 8, 324–334 (2021).
Kulce, O. & Onural, L. Generation of a polarized optical field from a given scalar field for wide-viewing-angle holographic displays. Opt. Lasers Eng. 137, 106344 (2021).
Want to hear about the latest lighting trends and designs, as well as receiving exclusive offers from Lighting Direct, join the club.
Goodman, J. W., Dias, A. R. & Woody, L. M. Fully parallel, high-speed incoherent optical method for performing discrete Fourier transforms. Opt. Lett. 2, 1–3 (1978).
In addition to the all-optical transformation error, cosine similarity, and output MSE metrics, the output diffraction efficiency is another very important metric as it determines the signal-to-noise ratio of the resulting all-optical transformation. When we compare the diffraction efficiencies of different networks, we observe that the data-free, matrix pseudoinverse-based designs perform the worst among all the configurations that we have explored (see Fig. 1f, 4f, 7f, 10f, and Supplementary Figs. S1f, S4f, S7f). This is majorly caused by the larger magnitudes of the transmittance values of the neurons that are located close to the edges of the diffractive layer, when compared to the neurons at the center of the same layer. Since these “edge” neurons are further away from the input FOV, their larger transmission magnitudes (|t|) compensate for the significantly weaker optical power that falls onto these edge neurons from the input FOV. Since we are considering here passive diffractive layers only, the magnitude of the transmittance value of an optical neuron cannot be larger than one (i.e., |t| ≤ 1), and therefore as the edge neurons in a data-free design start to get more transmissive to make up for the weaker input signals at their locations, the transmissivity of the central neurons of the diffractive layer become lower, balancing off their relative powers at the output FOV to be able to perform an arbitrary linear transformation. This is at heart of the poor diffraction efficiency that is observed with data-free, matrix pseudoinverse-based designs. In fact, the same understanding can also intuitively explain why deep learning-based diffractive designs prefer to distribute their trainable diffractive neurons into multiple layers. By dividing their total trainable neuron budget (N) into multiple layers, deeper diffractive designs (e.g., K = 4) avoid using neurons that are laterally further away from the center. This way, the synthesis of an arbitrary all-optical transformation can be achieved much more efficiently, without the need to weaken the transmissivity of the central neurons of a given layer. Stated differently, deep learning-based diffractive designs utilize a given neuron budget more effectively and can efficiently perform an arbitrary complex-valued transformation between an input and output FOV.
The focal length of a lens also affects the depth of field of an image. (Depth of field refers to the range of distances that appear acceptably sharp in the image.) A longer focal length results in a shallower depth of field, while a shorter focal length results in a deeper depth of field.
It is well-known that optical waves can be utilized for the processing of spatial and/or temporal information1,2,3,4,5,6. Using optical waves to process information is appealing since computation can be performed at the speed of light, with high parallelization and throughput, also providing potential power advantages. For this broad goal, various optical computing architectures have been demonstrated in the literature7,8,9,10,11,12,13,14,15,16,17,18,19,20,21. With the recent advances in photonic material engineering, e.g., metamaterials, metasurfaces, and plasmonics, the utilization of advanced diffractive materials that can precisely shape optical wavefronts through light-matter interaction has become feasible22,23,24,25,26,27. For example, optical processors formed through spatially-engineered diffractive surfaces have been shown to achieve both statistical inference and deterministic tasks, such as image classification, single-pixel machine vision, and spatially-controlled wavelength division multiplexing, among others28,29,30,31,32,33,34,35,36,37.
For a given randomly generated permutation matrix (P), the task of the diffractive design is to all-optically obtain the permuted version of the input complex-field at the output FOV. Although the target ground truth matrix (P) for this case is real-valued and relatively simpler compared to that of e.g., the 2D Fourier transform matrix, an all-optical permutation operation that preserves the phase and amplitude of each point is still rather unconventional and challenging to realize using standard optical components. To demonstrate this capability, we randomly selected a permutation matrix as shown in Fig. 10b and designed various diffractive surfaces to all-optically perform this target permutation operation at the output FOV. The performances of these data-free and data-driven, deep learning-based diffractive designs are compared in Fig. 10c–f. The success of the diffractive all-optical transformations, matching the target permutation operation is demonstrated when N ≥ NiNo, revealing the same conclusions discussed earlier for the other transformation matrices that were tested. For example, deep learning-based diffractive designs (K = 4) with N ≥ NiNo neurons were successful in performing the randomly selected permutation operation all-optically, and achieved a transformation error and output MSE of ~0, together with a cosine similarity of ~1 (see Fig. 10). Estimated transforms and sample output patterns, together with their differences with respect to the corresponding ground truths are also reported in Figs. 11 and 12, respectively, further demonstrating the success of the presented diffractive designs.
Focus distance
where t1[l] = T1[l,l] and \({{{\boldsymbol{H}}}}^\prime \left[ {:,l} \right] = {{{\boldsymbol{H}}}}_{d_1}^{\prime T}\left[ {:,l} \right] \otimes {{{\boldsymbol{H}}}}_{d_2}^\prime \left[ {:,l} \right]\) for \(l \in \left\{ {1,2,\, \cdots ,N_{L_1}} \right\}\), and [:, l] represents the lth column of the associated matrix in our notation. Here the matrix H′ has size \(N_iN_o \times N_{L_1}\) and is a full-rank matrix with rank \(D = {\it{{\rm{min}}}}\left( {N_iN_o,N_{L_1}} \right)\) for d1 ≠ d2. If d1 = d2, the maximum rank reduces to Ni(Ni + 1)/2 when Ni = No35. We assume that d1 ≠ d2 and denote the maximum achievable rank as Dmax, which is equal to NiNo.
To obtain the diffractive surface patterns that collectively approximate the target transformation using deep learning-based training, we generated a complex-valued input-output image dataset for each target A. To cover a wide range of spatial patterns, each input image in the dataset has a different sparsity ratio with randomly chosen pixel values. We also included rotated versions of each training image. We can summarize our input image dataset as
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
Athale, R. A. & Collins, W. C. Optical matrix–matrix multiplier based on outer product decomposition. Appl. Opt. 21, 2089–2090 (1982).
For example, if you take a portrait with a wide-angle lens, the subject's nose and face will appear larger than they are in reality. This is because the lens exaggerates the distance between the nose and the ears, making the nose appear larger. A telephoto lens, on the other hand, compresses the distance between the nose and the ears, making the face appear flatter.
In order to further increase the output diffraction efficiency of our designs, we adopted an additional strategy that includes a diffraction efficiency-related penalty term in the loss function (detailed in the section “Penalty term for improved diffraction efficiency”). Performance quantification of these diffraction efficient designs that have different loss function parameters is shown in Supplementary Fig. S14 for a unitary transform; the same figure also includes the comparison between the complex-valued and phase-only modulation schemes that do not have a diffraction efficiency-related penalty term in their loss functions. The analyses shown in Supplementary Fig. S14 indicate that the output diffraction efficiency of the network can be significantly improved and maintained almost constant among different designs with different numbers of neurons by the introduction of the diffraction efficiency-related penalty term during the training. Moreover, the transformation error, cosine similarity and MSE performance of the complex-valued modulation scheme that has no diffraction efficiency term can be approximately matched through this new training strategy that includes an additional loss term dedicated to improve diffraction efficiency.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
In this section we present a quantitative comparison of the pseudoinverse- and deep learning-based methods in synthesizing various all-optical linear transformations between the input and output FOVs using diffractive surfaces. In our analysis, we took the total number of pixels in both the input and output FOVs as Ni = No = 64 (i.e., 8 × 8) and the size of each Hd matrix was 1442 × 1442 with Nd = 1442. The linear transformations that we used as our comparison testbeds are (i) arbitrarily generated complex-valued unitary transforms, (ii) arbitrarily generated complex-valued nonunitary and invertible transforms, (iii) arbitrarily generated complex-valued noninvertible transforms, (iv) the 2D discrete Fourier transform, (v) a permutation matrix-based transformation, and (vi) a high-pass filtered coherent imaging operation. The details of the diffractive network configurations, training image datasets, training parameters, computation of error metrics and the generation of ground truth transformation matrices are presented in “Materials and methods” section. Next, we present the performance comparisons for different all-optical transformations.
Edmund Optics has been a leading producer of optics, imaging, and laser optics for 80 years. Discover the latest optical and imaging technology.
Based on these definitions, the relationship between the input and output FOVs for a diffractive network that has K diffractive layers can be written as
The focal length of a lens affects the perspective of the image. A wide-angle lens exaggerates the distance between the foreground and the background, making the background appear further away than it really is. A telephoto lens compresses the distance between the foreground and the background, making them appear closer together.
Estakhri, N. M., Edwards, B. & Engheta, N. Inverse-designed metastructures that solve equations. Science 363, 1333–1338 (2019).
To increase the diffraction efficiency at the output FOV of a diffractive network design, we used the following modified loss function:
If you're shooting with a wide-angle lens and using a smaller aperture, like f/11, the entire scene will be in focus. This works well for landscape photography, where you want everything from the foreground to the background to be sharp.
To implement the wave propagation between parallel planes in free space, we generate a matrix, Hd, where d is the axial distance between two planes (e.g., d ≥ λ). Since this matrix represents a convolution operation where the 2D impulse response originates from the Rayleigh-Sommerfeld diffraction formulation3, it is a Toeplitz matrix41. We generate this matrix using the Fourier relation in the discrete domain as
Here we show that the 2D Fourier transform operation can be performed using diffractive designs such that the complex field at output FOV reflects the 2D discrete Fourier transform of the input field. Compared to lens-based standard Fourier transform operations, diffractive surface-based solutions are not based on the paraxial approximation and offer a much more compact set-up (with a significantly smaller axial distance, e.g., <50λ, between the input-output planes) and do not suffer from aberrations, which is especially important for larger input/output FOVs.
a Schematic of a K-layer diffractive network, that all-optically performs a linear transformation between the input and output fields-of-views that have Ni and No pixels, respectively. The all-optical transformation matrix due to the diffractive layer(s) is given by A′. b. The magnitude and phase of the ground truth (target) input-output transformation matrix, which is an arbitrarily generated complex-valued unitary transform, i.e., \({{{\boldsymbol{R}}}}_{{{\mathrm{1}}}}^{{{\mathrm{H}}}}{{{\boldsymbol{R}}}}_{{{\mathrm{1}}}}^{\hphantom{}} = {{{\boldsymbol{R}}}}_{{{\mathrm{1}}}}^{\hphantom{}}{{{\boldsymbol{R}}}}_{{{\mathrm{1}}}}^{{{\mathrm{H}}}} = {{{\boldsymbol{I}}}}\). c All-optical transformation errors (see Eq. 5). The x-axis of the figure shows the total number of neurons (N) in a K-layered diffractive network, where each diffractive layer includes N/K neurons. Therefore, for each point on the x-axis, the comparison among different diffractive designs (colored curves) is fair as each diffractive design has the same total number of neurons available. The simulation data points are shown with dots and the space between the dots are linearly interpolated. d Cosine similarity between the vectorized form of the target transformation matrix in (b) and the resulting all-optical transforms (see Eq. 16). e Output MSE between the ground-truth output fields and the estimated output fields by the diffractive network (see Eq. 18). f The diffraction efficiency of the designed diffractive networks (see Eq. 19)
Oppenheim, A. V., Schafer, R. W. & Buck, J. R. Discrete-Time Signal Processing (Prentice Hall, Upper Saddle River, 1999).
Finally, the transformation matrix corresponding to the high-pass filtering operation, as shown in Supplementary Fig. S7b, is generated from the Laplacian high-pass filter whose 2D convolution kernel is
Moon, T. K. & Stirling, W. C. Mathematical Methods and Algorithms for Signal Processing (Upper Saddle River: Prentice Hall, 2000).
Focal length is the distance between the optical centre of your camera lens and your camera's image sensor or film when the lens is focused on infinity. It is usually measured in millimeters (mm). The focal length of a lens determines its field of view and magnification. A lens with a shorter focal length has a wider field of view, while a lens with a longer focal length has a narrower field of view.
focallength是什么
where H′† is the pseudoinverse of H′. This pseudoinverse operation is performed using the singular value decomposition (SVD) as
Based on Eq. 4, the computation of the neuron transmission values of the diffractive layer that approximates a given complex-valued transformation matrix A can be reduced to an L2-norm minimization problem, where the approximation error which is subject to the minimization is41
If \(N_{L_1} \,>\, N_iN_o\), the number of equations in Eq. 4 becomes less than the number of unknowns and the matrix-vector equation corresponds to an underdetermined system. If \(N_{L_1} \,<\, N_iN_o\), on the other hand, the equation system becomes an overdetermined system. In the critical case, where \(N_{L_1} = N_iN_o\), H′ becomes a full-rank square matrix, hence, is an invertible matrix. There are various numerical methods for solving the formulated matrix-vector equation and minimizing the transformation error given in Eq. 541. In this paper, we adopt the pseudoinverse-based method among other numerical methods in computing the neuron transmission values in finding the estimate transformation A′ for all the cases, i.e., \(N_{L_1} \,>\, N_iN_o\), \(N_{L_1} \,<\, N_iN_o\) and \(N_{L_1} = N_iN_o\). For this, we compute the neuron values from a given target transformation as
The associated transform matrix (A) corresponding to 2D discrete Fourier transform, all-optical transformation error, cosine similarity of the resulting all-optical transforms with respect the ground truth, the output MSE and the diffraction efficiency are shown in Fig. 7. For all these curves and metrics, our earlier conclusions made in the section “Arbitrary complex-valued unitary and nonunitary transforms” are also applicable. Data-free (K = 1) and deep learning-based (K = 4) diffractive designs achieve accurate results at the output FOV for N ≥ NiNo = 642, where the transformation error and the output MSE both approach to ~0 while the cosine similarity reaches ~1, as desired. In terms of the diffraction efficiency at the output FOV, similar to our earlier observations in the previous section, deep learning-based diffractive designs offer major advantages over data-free diffractive designs. Further advantages of deep learning-based diffractive designs over their data-free counterparts include significantly improved output MSE and reduced transformation error for N < NiNo, confirming our earlier conclusions made in the section “Arbitrary complex-valued unitary and nonunitary transforms”.
To further show the success of the diffractive designs in approximating the 2D discrete Fourier transformation, in Fig. 8 we report the estimated transformations and their differences (in phase and amplitude) from the target 2D discrete Fourier transformation matrix for different diffractive designs. Furthermore, in Fig. 9, examples of complex-valued input-output fields for different diffractive designs are compared against the ground truth output fields (calculated using the 2D discrete Fourier transformation), along with the resulting phase and amplitude errors at the output FOV, all of which illustrate the success of the presented diffractive designs.
Our results reveal that when the total number of engineered/optimized diffractive neurons of a material design exceeds Ni × No, both the data-free and data-driven diffractive designs successfully approximate the target linear transformation with negligible error; here, Ni and No refer to the number of diffraction-limited, independent spots/pixels located within the area of the input and output FOVs, respectively. This means, to all-optically perform an arbitrary complex-valued linear transformation between larger input and/or larger output FOVs, larger area diffractive layers with more neurons or a larger number of diffractive layers need to be utilized. Our analyses further reveal that deep learning-based data driven diffractive designs (that learn a target linear transformation through examples of input/output fields) overall achieve much better diffraction efficiency at the output FOV. All in all, our analysis confirms that for a given diffractive layer size, with a certain number of diffractive features per layer (like a building block of a diffractive network), the creation of deeper diffractive networks with one layer following another, can improve both the transformation error and the diffraction efficiency of the resulting all-optical transformation.
In Figs. 1–3 and Supplementary Figs. S1–S3, we present the results for two different arbitrarily selected complex-valued unitary transforms that are approximated using diffractive surface designs with different number of diffractive layers, K, and different number of neurons, \(N = \mathop {\sum}\nolimits_{k = 1}^K {N_{L_k}}\). Similarly, Figs. 4–6 and Supplementary Figs. S4–S6 report two different nonunitary, arbitrarily selected complex-valued linear transforms performed through diffractive surface designs. To cover different types of transformations, Figs. 4–6 and Supplementary Figs. S4–S6 report an invertible nonunitary and a noninvertible (hence, nonunitary) transformation, respectively. The magnitude and phase values of these target transformations (A) are also shown in Figs. 1b, 4b, and Supplementary Figs. S1b and S4b.
\(\left| {\angle {{{\boldsymbol{A}}}} - \angle \widehat {{{\boldsymbol{A}}}}^\prime } \right|_\pi\) indicates the wrapped phase difference between the ground truth and the normalized all-optical transformation
The magnitude and phase of the normalized output fields and the differences of these quantities with respect to the ground truth are shown. \(\left| {\angle {{{\boldsymbol{o}}}} - \angle \widehat {{{\boldsymbol{o}}}}^\prime } \right|_\pi\) indicates wrapped phase difference between the ground truth and the normalized output field
Ozaktas, H. M., Zalevsky, Z. & Kutay, M. A. The Fractional Fourier Transform: With Applications in Optics and Signal Processing. (Wiley, New York, 2001).
The magnitude and phase of the normalized output fields and the differences of these quantities with respect to the ground truth are shown. \(\left| {\angle {{{\boldsymbol{o}}}} - \angle \widehat {{{\boldsymbol{o}}}}^\prime } \right|_\pi\) indicates wrapped phase difference between the ground truth and the normalized output field
a Schematic of a K-layer diffractive network, that all-optically performs a linear transformation between the input and output fields-of-views that have Ni and No pixels, respectively. The all-optical transformation matrix due to the diffractive layer(s) is given by A′. b. The magnitude and phase of the ground truth (target) input-output transformation matrix, which is an arbitrarily generated complex-valued nonunitary and invertible transform. c All-optical transformation errors (see Eq. 5). The x-axis of the figure shows the total number of neurons (N) in a K-layered diffractive network, where each diffractive layer includes N/K neurons. Therefore, for each point on the x-axis, the comparison among different diffractive designs (colored curves) is fair as each diffractive design has the same total number of neurons available. The simulation data points are shown with dots and the space between the dots are linearly interpolated. d Cosine similarity between the vectorized form of the target transformation matrix in (b) and the resulting all-optical transforms (see Eq. 16). e Output MSE between the ground-truth output fields and the estimated output fields by the diffractive network (see Eq. 18). f The diffraction efficiency of the designed diffractive networks (see Eq. 19)
To prevent the occurrence of excessively large numbers that might cause numerical artifacts, we take very small singular values as zero during the computation of ∑−1. After computing \({{{\hat{\boldsymbol t}}}}_1\), the normalization constant (m) and the physically realizable neuron values can be calculated as:
where W and W−1 are the 2D discrete Fourier transform (DFT) and inverse discrete Fourier transform (IDFT) matrices, respectively, and the superscript H represents the matrix Hermitian operation. We choose the scaling constant appropriately such that the unitarity of the DFT operation is preserved, i.e., W−1 = WH 41. The matrix, D, represents the transfer function of free space propagation in the 2D Fourier domain and it includes nonzero elements only along its main diagonal entries. These entries are the samples of the function, \(e^{jk_zd}\), for \(0 \le k_z = \sqrt {k^2 - \left( {k_x^2 + k_y^2} \right)} \le k\), where kx, ky ∈ [−k, k). Here k = 2π/λ is the wavenumber of the monochromatic optical field and (kx, ky) pair represents the 2D spatial frequency variables along x and y directions, respectively3. To ignore the evanescent modes, we choose the diagonal entries of D that correspond to the kz values for \(k^2 \le k_x^2 + k_y^2\) as zero; since d ≥ λ, this is an appropriate selection. In our model, we choose the 2D discrete wave propagation square window size, \(\sqrt {N_d} \times \sqrt {N_d}\), large enough (e.g., Nd = 1442) such that the physical wave propagation between the input plane, diffractive layers and the output plane is simulated accurately42. Also, since Hd represents a convolution in 2D space, the entries of W, W−1, and D follow the same vectorization procedure applied to the input and output FOVs. As a result, the sizes of all these matrices become Nd × Nd.
Other details of this deep learning-based, data-driven design of diffractive layers are presented in the section “Image datasets and diffractive network training parameters“. After the training is over, which is a one-time effort, the estimate transformation matrix and the corresponding vectorized form, A′ and vec(A′) = a′, are computed using the optimized neuron transmission values in Eq. 2. After computing a′, we also compute the normalization constant, m, which minimizes ‖a − ma′‖2, resulting in:
On top of transformation error, output MSE and diffraction efficiency metrics, Fig. 1d, Supplementary Fig. S1d, Fig. 4d, and Supplementary Fig. S4d also report the cosine similarity (see “Materials and methods” section) between the estimated all-optical transforms and the ground truth (target) transforms. These cosine similarity curves show the same trend and support the same conclusions as with the transformation error curves reported earlier; this is not surprising as the transformation error and cosine similarity metrics are analytically related to each other as detailed in the section “Computation of all-optical transformation performance metrics”. For N ≥ 642 = NiNo, the cosine similarity approaches 1, matching the target transformations using both the data-free (K = 1) and deep learning-based (K = 4) diffractive designs as shown in Fig. 1d, Supplementary Fig. S1d, Fig. 4d and Supplementary Fig. S4d.
3 Pin to 5 Pin. Use this connector to bridge the gap between 3 Pin DMX fixtures and 5 Pin DMX cables. · Solid and Reliable. Made from the finest materials, these ...
Dinc, N. U. et al. Computer generated optical volume elements by additive manufacturing. Nanophotonics 9, 4173–4181 (2020).
where Re{∙} operator extracts the real part of its input. As a result, apart from the vector normalization constants, ‖a‖2 and \(\left\| {{{{\hat{\boldsymbol a}}}}^\prime } \right\|^2\), Eqs. 16 and 17 deal with the magnitude and real part of the inner product \(\left( {{{{\boldsymbol{a}}}}^H{{{\hat{\boldsymbol a}}}}^\prime } \right)\), respectively.
Kulce, O., Mengu, D., Rivenson, Y. et al. All-optical synthesis of an arbitrary linear transformation using diffractive surfaces. Light Sci Appl 10, 196 (2021). https://doi.org/10.1038/s41377-021-00623-5
DL Wu · 2021 · 5 — The ISS/CTI objective was to demonstrate the strained layer superlattice (SLS) detector technology with a simple camera. As a result, the CTI detector's ...
CameraFOV calculator
In addition to these, one of the most significant differences between the pseudoinverse-based data-free diffractive designs and deep learning-based counterparts is observed in the optical diffraction efficiencies calculated at the output FOV; see Fig. 1f, 4f, and Supplementary Figs. 1f and Supplementary Fig. S4f. Even though the transformation errors (or the output MSE values) of the two design approaches remain the same (~0) for N ≥ 642 = NiNo, the diffraction efficiencies of the all-optical transformations learned using deep learning significantly outperform the diffraction efficiencies achieved using data-free, matrix pseudoinverse-based designs as shown in Fig. 1f, Supplementary Fig. S1f, Fig. 4f and Supplementary Fig. S4f.
where LM is the MSE loss term which is given in Eq. 10 and LD is the additional loss term that penalizes poor diffraction efficiency:
Since the diffractive surfaces are modeled as thin elements, the light transmission through surfaces can be formulated as a pointwise multiplication operation, where the output optical field of a layer equals to its input optical field multiplied by the complex-valued transmission function, t(x, y), of the diffractive layer. Hence, in matrix formulation, this is represented by a diagonal matrix T, where the diagonal entries are the vectorized samples of t(x, y). Hence the size of T becomes NL × NL, where NL is the total number of diffractive features (referred to as neurons) on the corresponding layer.
Our results and conclusions can be broadly applied to any part of the electromagnetic spectrum to design all-optical processors using spatially-engineered diffractive surfaces to perform an arbitrary complex-valued linear transformation.
\(\left| {\angle {{{\boldsymbol{A}}}} - \angle \widehat {{{\boldsymbol{A}}}}^\prime } \right|_\pi\) indicates the wrapped phase difference between the ground truth and the normalized all-optical transformation
The crop factor depends on the camera's sensor size. For example, a crop factor of 1.5x means that a 50mm lens on a crop sensor camera will have an effective focal length of 75mm.
The compact Pulsar family is designed for beginners and pros alike. Simple charging meets advanced capabilities so you can enjoy going electric.



 Ms.Cici
Ms.Cici 
 8618319014500
8618319014500