
LED flood lights for outdoor sports - led sport light
Visiondocumentation
Chen, Xiangning, et al. “When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations.” arXiv preprint arXiv:2106.01548 (2021). link
In conclusion, aspherical camera lenses, with their non-spherical surface design, represent a vital breakthrough in modern photography. By effectively correcting optical aberrations and producing higher image quality, they have become indispensable tools for photographers across various genres. Their ability to deliver sharp, distortion-free images, especially in wide-angle scenarios, makes them a preferred choice for many photography enthusiasts and professionals alike. Despite their higher cost and potential lens flare concerns, the advantages they offer far outweigh the drawbacks, making aspherical lenses an essential asset in the pursuit of capturing stunning and breathtaking images.
VisionPython
Finally, we can put everything into a PyTorch Lightning Module as usual. We use torch.optim.AdamW as the optimizer, which is Adam with a corrected weight decay implementation. Since we use the Pre-LN Transformer version, we do not need to use a learning rate warmup stage anymore. Instead, we use the same learning rate scheduler as the CNNs in our previous tutorial on image classification.
After we have looked at the preprocessing, we can now start building the Transformer model. Since we have discussed the fundamentals of Multi-Head Attention in Tutorial 6, we will use the PyTorch module nn.MultiheadAttention (docs) here. Further, we use the Pre-Layer Normalization version of the Transformer blocks proposed by Ruibin Xiong et al. in 2020. The idea is to apply Layer Normalization not in between residual blocks, but instead as a first layer in the residual blocks. This reorganization of the layers supports better gradient flow and removes the necessity of a warm-up stage. A visualization of the difference between the standard Post-LN and the Pre-LN version is shown below.
A linear projection layer that maps the input patches to a feature vector of larger size. It is implemented by a simple linear layer that takes each \(M\times M\) patch independently as input.
NLPtutorial
Aspherical lenses, by their design, help to mitigate spherical aberration, leading to improved focusing of light rays and producing images with better clarity and sharpness.
We load the CIFAR10 dataset below. We use the same setup of the datasets and data augmentations as for the CNNs in Tutorial 5 to keep a fair comparison. The constants in the transforms.Normalize correspond to the values that scale and shift the data to a zero mean and standard deviation of one.
An MLP head that takes the output feature vector of the CLS token, and maps it to a classification prediction. This is usually implemented by a small feed-forward network or even a single linear layer.
ComputerVision Tutorial
Feel free to explore the hyperparameters yourself by changing the values below. In general, the Vision Transformer did not show to be too sensitive to the hyperparameter choices on the CIFAR10 dataset.
Xiong, Ruibin, et al. “On layer normalization in the transformer architecture.” International Conference on Machine Learning. PMLR, 2020. link
A classification token that is added to the input sequence. We will use the output feature vector of the classification token (CLS token in short) for determining the classification prediction.
Let’s take a look at how that works for our CIFAR examples above. For our images of size \(32\times 32\), we choose a patch size of 4. Hence, we obtain sequences of 64 patches of size \(4\times 4\). We visualize them below:
Vision tutorialroblox
Spherical aberration is a common optical phenomenon that occurs in lenses with a uniform curvature, such as spherical lenses. It causes light rays passing through the edges of the lens to converge at a different focal point than those passing through the center. As a result, the image may appear blurred or lack sharpness.
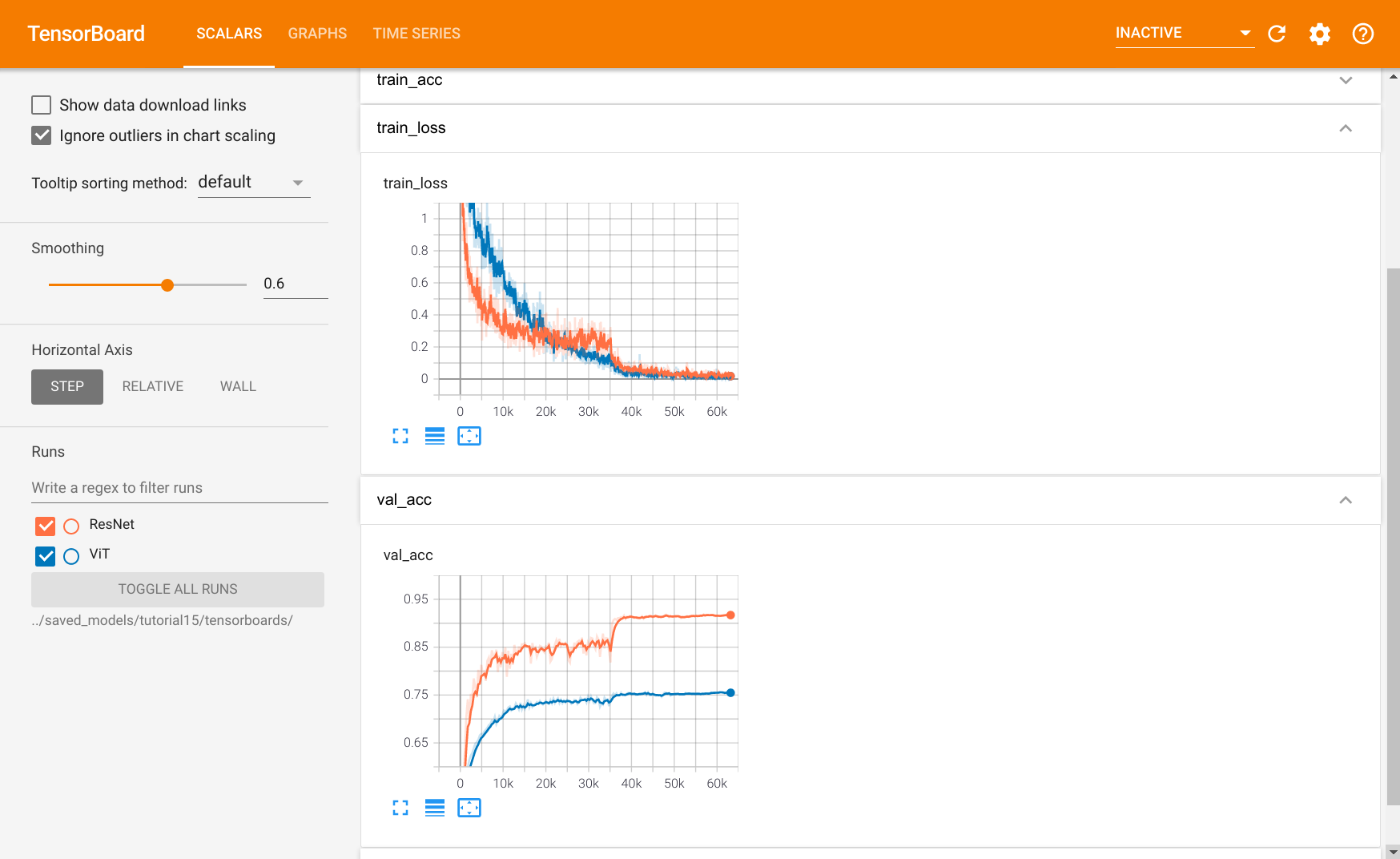
The Vision Transformer achieves a validation and test performance of about 75%. In comparison, almost all CNN architectures that we have tested in Tutorial 5 obtained a classification performance of around 90%. This is a considerable gap and shows that although Vision Transformers perform strongly on ImageNet with potential pretraining, they cannot come close to simple CNNs on CIFAR10 when being trained from scratch. The differences between a CNN and Transformer can be well observed in the training curves. Let’s look at them in a tensorboard below:
Computervisionoverview
All those observed phenomenons can be explained with a concept that we have visited before: inductive biases. Convolutional Neural Networks have been designed with the assumption that images are translation invariant. Hence, we apply convolutions with shared filters across the image. Furthermore, a CNN architecture integrates the concept of distance in an image: two pixels that are close to each other are more related than two distant pixels. Local patterns are combined into larger patterns until we perform our classification prediction. All those aspects are inductive biases of a CNN. In contrast, a Vision Transformer does not know which two pixels are close to each other, and which are far apart. It has to learn this information solely from the sparse learning signal of the classification task. This is a huge disadvantage when we have a small dataset since such information is crucial for generalizing to an unseen test dataset. With large enough datasets and/or good pre-training, a Transformer can learn this information without the need for inductive biases, and instead is more flexible than a CNN. Especially long-distance relations between local patterns can be difficult to process in CNNs, while in Transformers, all patches have the distance of one. This is why Vision Transformers are so strong on large-scale datasets such as ImageNet but underperform a lot when being applied to a small dataset such as CIFAR10.
The tensorboard compares the Vision Transformer to a ResNet trained on CIFAR10. When looking at the training losses, we see that the ResNet learns much more quickly in the first iterations. While the learning rate might have an influence on the initial learning speed, we see the same trend in the validation accuracy. The ResNet achieves the best performance of the Vision Transformer after just 5 epochs (2000 iterations). Further, while the ResNet training loss and validation accuracy have a similar trend, the validation performance of the Vision Transformers only marginally changes after 10k iterations while the training loss has almost just started going down. Yet, the Vision Transformer is also able to achieve close to 100% accuracy on the training set.
Compared to the original images, it is much harder to recognize the objects from those patch lists now. Still, this is the input we provide to the Transformer for classifying the images. The model has to learn itself how it has to combine the patches to recognize the objects. The inductive bias in CNNs that an image is a grid of pixels, is lost in this input format.
Finally, the learning rate for Transformers is usually relatively small, and in papers, a common value to use is 3e-5. However, since we work with a smaller dataset and have a potentially easier task, we found that we are able to increase the learning rate to 3e-4 without any problems. To reduce overfitting, we use a dropout value of 0.2. Remember that we also use small image augmentations as regularization during training.
The main difference between spherical and aspherical lenses lies in their curvature. Spherical lenses have a constant curvature across the entire lens surface, resembling a perfect sphere. This results in limitations in correcting various optical aberrations, which can lead to decreased image quality, especially towards the edges of the frame.
Aspherical lenses are designed with complex surfaces, characterized by a combination of convex and concave curvature. This intricate shaping of the lens surface helps in gathering and transmitting light rays more efficiently, ultimately leading to improved image sharpness and reduced distortions.
Now, we can already start training our model. As seen in our implementation, we have a couple of hyperparameters that we have to set. When creating this notebook, we have performed a small grid search over hyperparameters and listed the best hyperparameters in the cell below. Nevertheless, it is worth discussing the influence that each hyperparameter has, and what intuition we have for choosing its value.
Commonly, Vision Transformers are applied to large-scale image classification benchmarks such as ImageNet to leverage their full potential. However, here we take a step back and ask: can Vision Transformer also succeed on classical, small benchmarks such as CIFAR10? To find this out, we train a Vision Transformer from scratch on the CIFAR10 dataset. Let’s first create a training function for our PyTorch Lightning module which also loads the pre-trained model if you have downloaded it above.
On the other hand, aspherical lenses have varying curvatures across their surfaces, deviating from the traditional spherical shape. This enables them to counteract a wider range of optical aberrations, producing sharper and more accurate images.
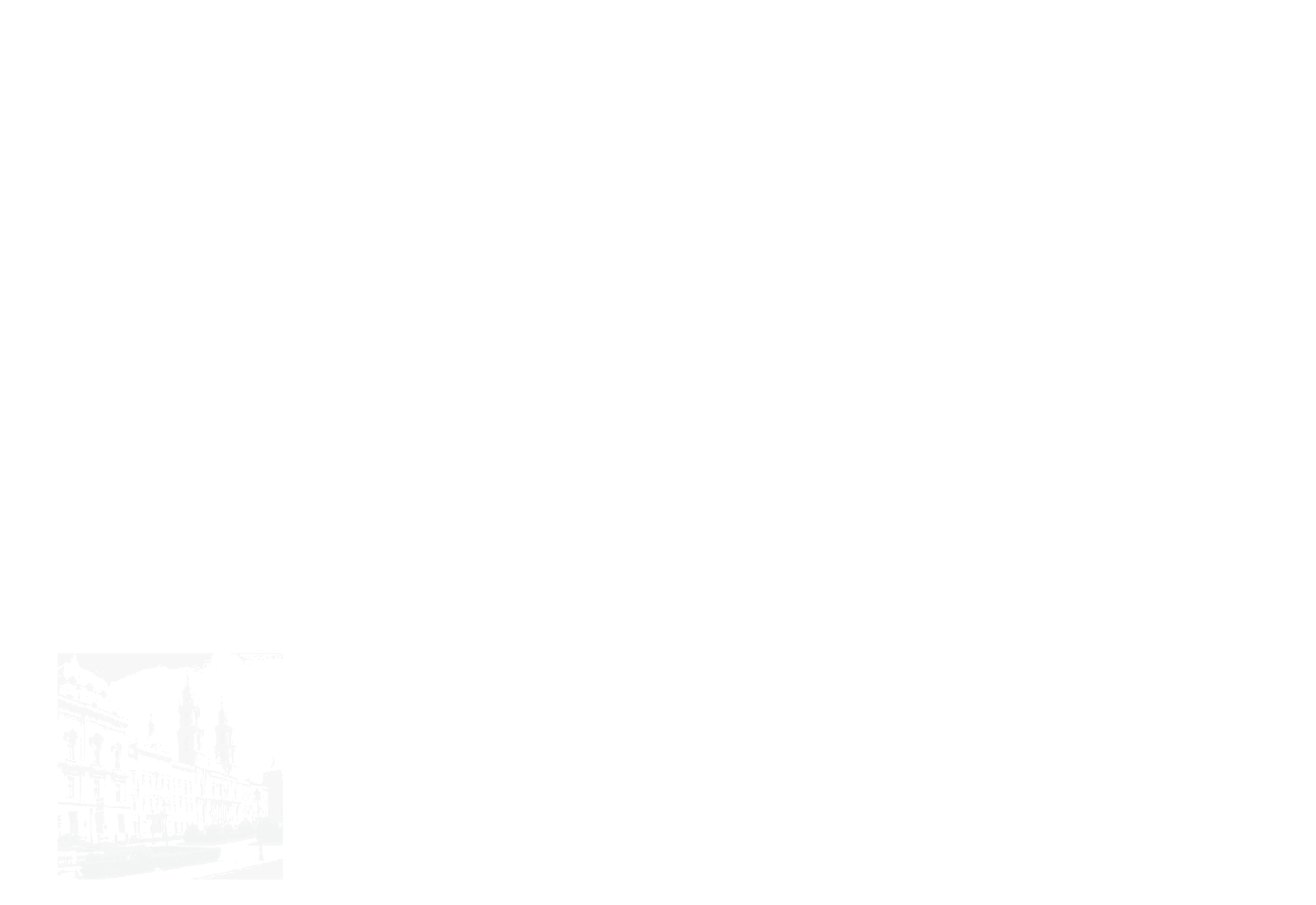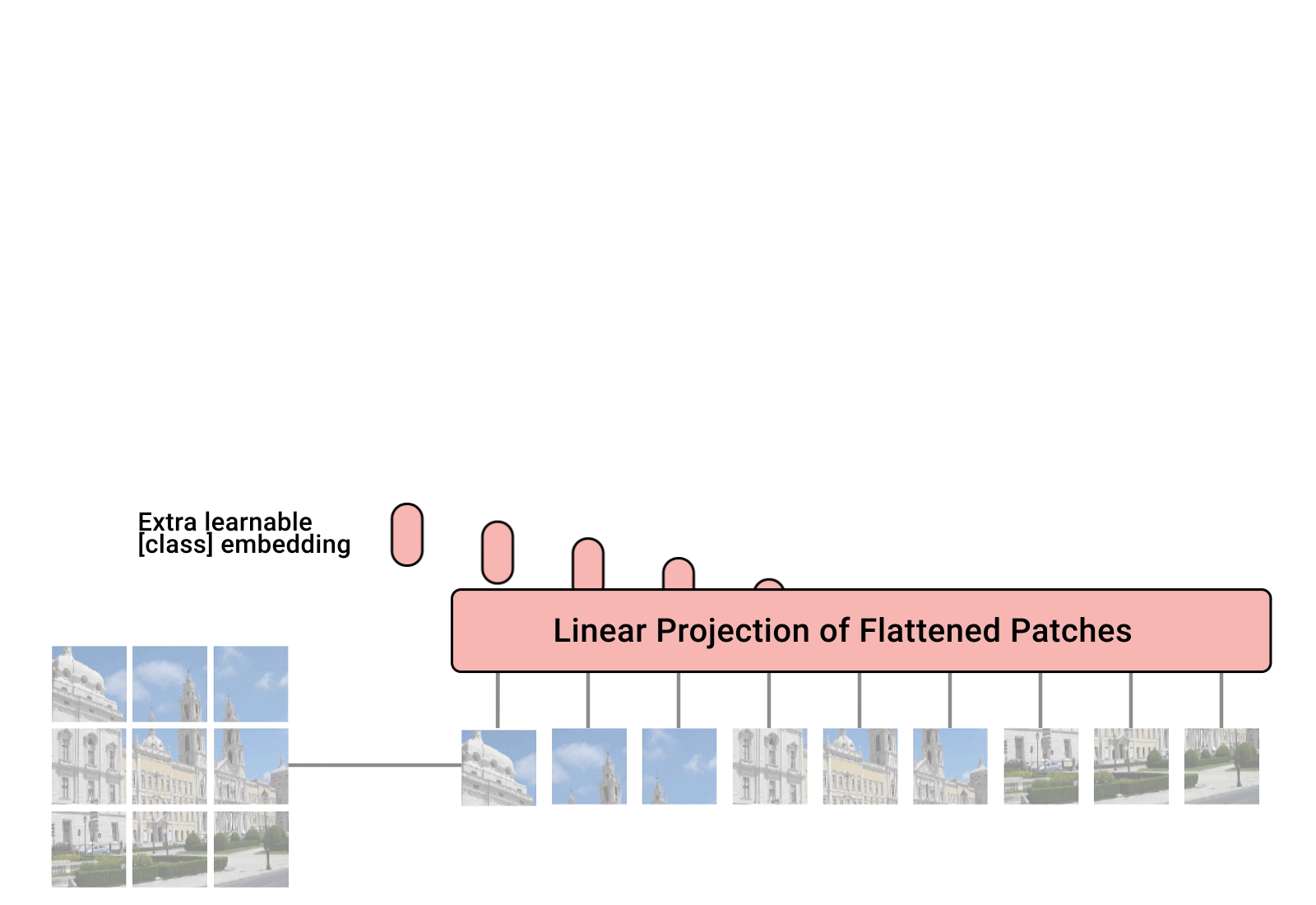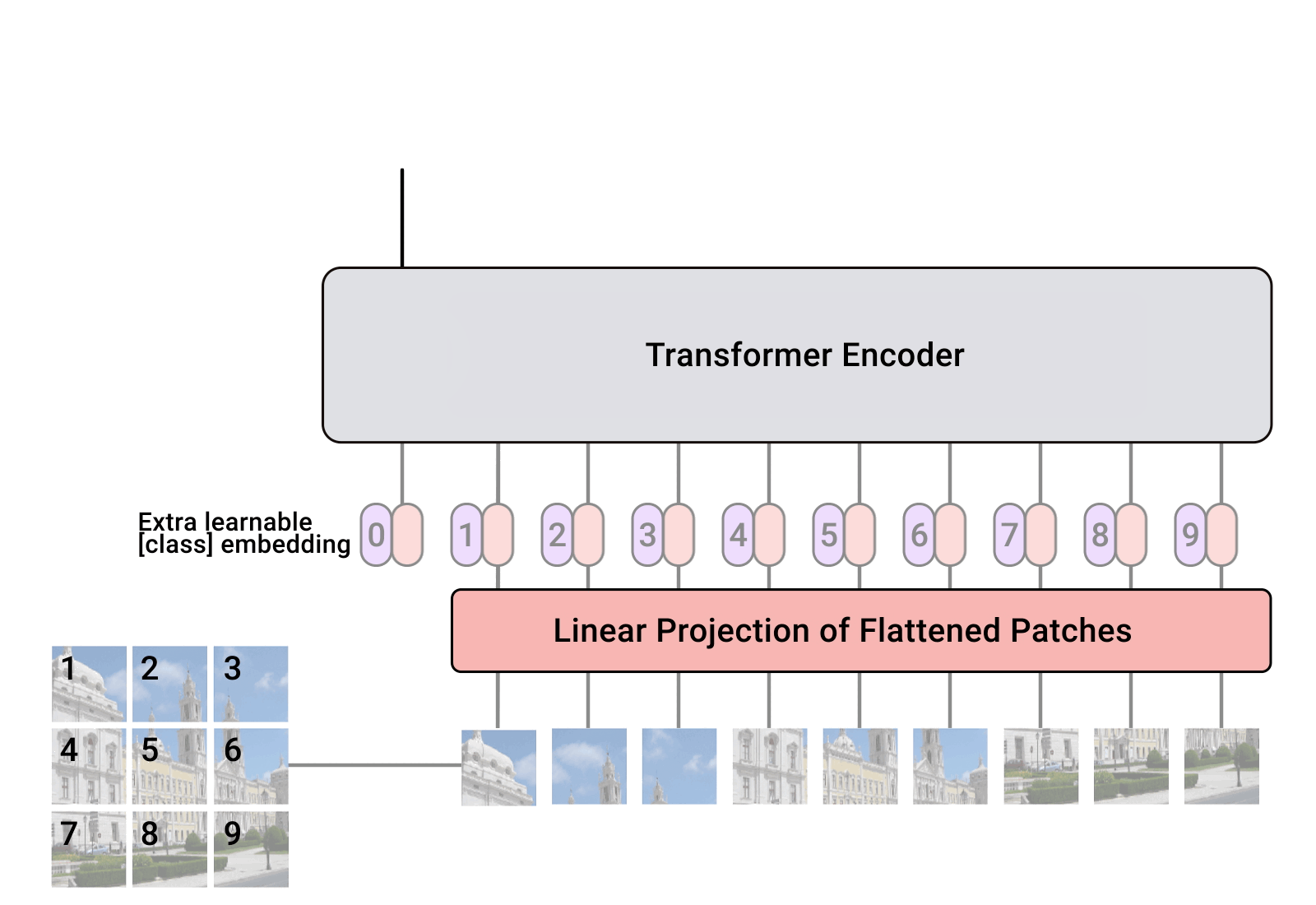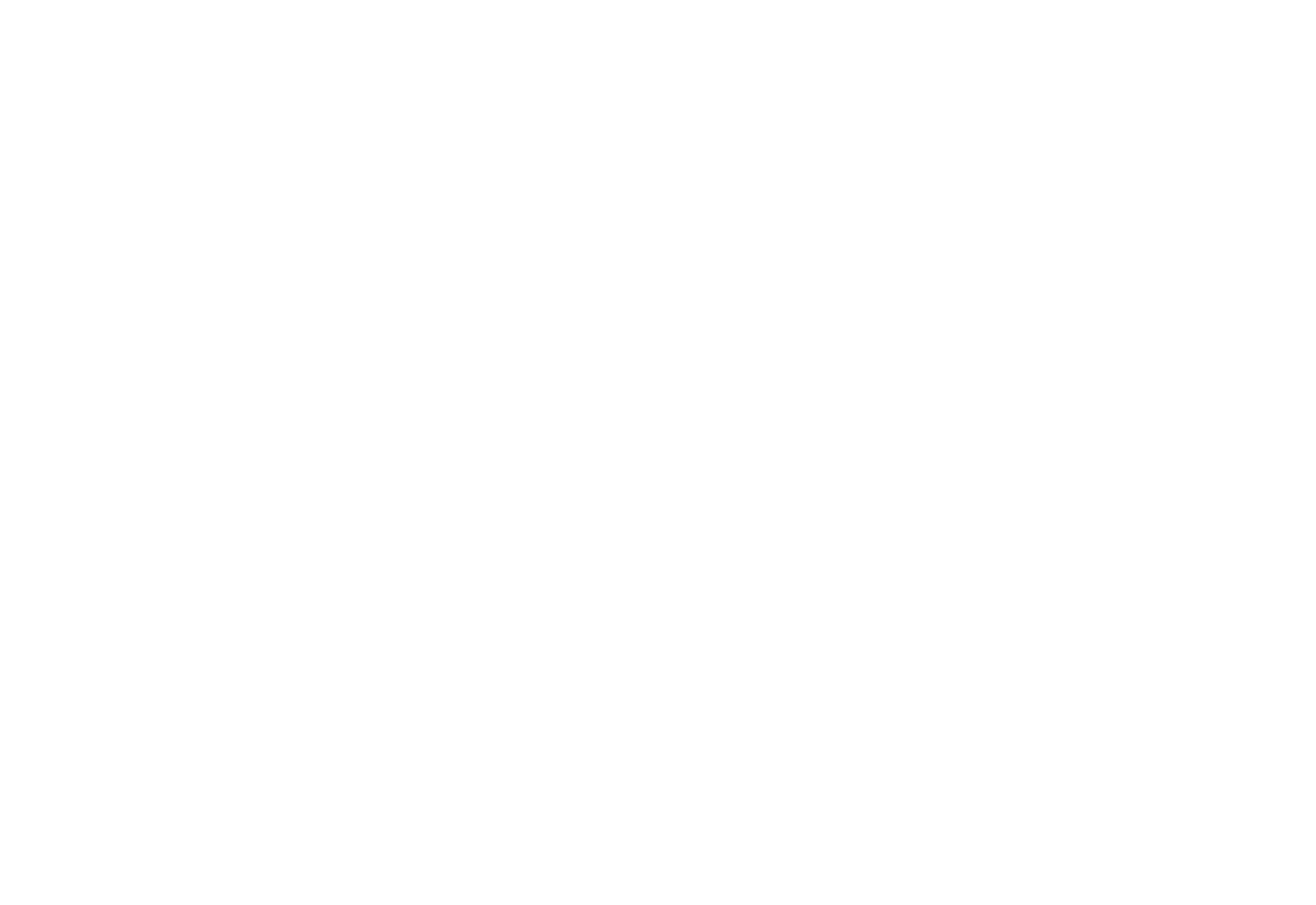
Computervision
Now we have all modules ready to build our own Vision Transformer. Besides the Transformer encoder, we need the following modules:
In this tutorial, we have implemented our own Vision Transformer from scratch and applied it to the task of image classification. Vision Transformers work by splitting an image into a sequence of smaller patches, use those as input to a standard Transformer encoder. While Vision Transformers achieved outstanding results on large-scale image recognition benchmarks such as ImageNet, they considerably underperform when being trained from scratch on small-scale datasets like CIFAR10. The reason is that in contrast to CNNs, Transformers do not have the inductive biases of translation invariance and the feature hierarchy (i.e. larger patterns consist of many smaller patterns). However, these aspects can be learned when enough data is provided, or the model has been pre-trained on other large-scale tasks. Considering that Vision Transformers have just been proposed end of 2020, there is likely a lot more to come on Transformers for Computer Vision.
Learnable positional encodings that are added to the tokens before being processed by the Transformer. Those are needed to learn position-dependent information, and convert the set to a sequence. Since we usually work with a fixed resolution, we can learn the positional encodings instead of having the pattern of sine and cosine functions.
Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” International Conference on Learning Representations (2021). link
Next, the embedding and hidden dimensionality have a similar impact on a Transformer as to an MLP. The larger the sizes, the more complex the model becomes, and the longer it takes to train. In Transformers, however, we have one more aspect to consider: the query-key sizes in the Multi-Head Attention layers. Each key has the feature dimensionality of embed_dim/num_heads. Considering that we have an input sequence length of 64, a minimum reasonable size for the key vectors is 16 or 32. Lower dimensionalities can restrain the possible attention maps too much. We observed that more than 8 heads are not necessary for the Transformer, and therefore pick an embedding dimensionality of 256. The hidden dimensionality in the feed-forward networks is usually 2-4x larger than the embedding dimensionality, and thus we pick 512.
First, let’s consider the patch size. The smaller we make the patches, the longer the input sequences to the Transformer become. While in general, this allows the Transformer to model more complex functions, it requires a longer computation time due to its quadratic memory usage in the attention layer. Furthermore, small patches can make the task more difficult since the Transformer has to learn which patches are close-by, and which are far away. We experimented with patch sizes of 2, 4, and 8 which gives us the input sequence lengths of 256, 64, and 16 respectively. We found 4 to result in the best performance and hence pick it below.
In this tutorial, we will take a closer look at a recent new trend: Transformers for Computer Vision. Since Alexey Dosovitskiy et al. successfully applied a Transformer on a variety of image recognition benchmarks, there have been an incredible amount of follow-up works showing that CNNs might not be optimal architecture for Computer Vision anymore. But how do Vision Transformers work exactly, and what benefits and drawbacks do they offer in contrast to CNNs? We will answer these questions by implementing a Vision Transformer ourselves and train it on the popular, small dataset CIFAR10. We will compare these results to the convolutional architectures of Tutorial 5.
If you are not familiar with Transformers yet, take a look at Tutorial 6 where we discuss the fundamentals of Multi-Head Attention and Transformers. As in many previous tutorials, we will use PyTorch Lightning again (introduced in Tutorial 5). Let’s start with importing our standard set of libraries.
Transformers have been originally proposed to process sets since it is a permutation-equivariant architecture, i.e., producing the same output permuted if the input is permuted. To apply Transformers to sequences, we have simply added a positional encoding to the input feature vectors, and the model learned by itself what to do with it. So, why not do the same thing on images? This is exactly what Alexey Dosovitskiy et al. proposed in their paper “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. Specifically, the Vision Transformer is a model for image classification that views images as sequences of smaller patches. As a preprocessing step, we split an image of, for example, \(48\times 48\) pixels into 9 \(16\times 16\) patches. Each of those patches is considered to be a “word”/“token” and projected to a feature space. With adding positional encodings and a token for classification on top, we can apply a Transformer as usual to this sequence and start training it for our task. A nice GIF visualization of the architecture is shown below (figure credit - Phil Wang):
Vision TutorialRanchi
We provide a pre-trained Vision Transformer which we download in the next cell. However, Vision Transformers can be relatively quickly trained on CIFAR10 with an overall training time of less than an hour on an NVIDIA TitanRTX. Feel free to experiment with training your own Transformer once you went through the whole notebook.
In the realm of photography, the aspherical camera lens, commonly abbreviated as ASPH lens, represents a significant technological advancement. Unlike traditional spherical lenses, which have a smooth, curved surface, aspherical lenses incorporate non-spherical elements that deviate from the standard spherical shape. These non-spherical elements allow the lens to better focus light, reducing various optical aberrations that can affect image quality.
We will walk step by step through the Vision Transformer, and implement all parts by ourselves. First, let’s implement the image preprocessing: an image of size \(N\times N\) has to be split into \((N/M)^2\) patches of size \(M\times M\). These represent the input words to the Transformer.



 Ms.Cici
Ms.Cici 
 8618319014500
8618319014500